

Релиз CedrusData 417-1
Новый cost-based оптимизатор, локальный дисковый кэш для ускорения работы с озерами данных, коннектор к Teradata

Общая информация
Релиз CedrusData 417-1 вышел 23 мая 2023 года и основан на Trino 417. Данный релиз содержит массивные улучшения производительности, а так же новый коннектор к СУБД Teradata.
Запуск из архива:
Запуск в Docker-контейнере:
Ключевые изменения
Локальный дисковый кэш данных
Документация: https://docs.cedrusdata.ru/latest/connector/hive.html#hive-data-cache.
Системы виртуализации данных, такие как Presto, Trino или Dremio, позволяют объединять информацию из удаленных источников. Это предоставляет пользователям возможность удобного доступа ко всем свои данным, но в то же время сопряжено с издержками на передачу данных по сети. Популярной стратегией оптимизацией работы с редко изменяющимися данными из озера данных является кэширование отдельных частей файлов непосредственно на вычислительных узлах. При наличии быстрых SSD дисков это позволяет существенно снизить задержки на доступ к данным по сети и ускорить выполнение запросов. Такой функционал присутствует в Presto и Dremio, но не доступен в стандартной версии Trino.
В версии CedrusData 417-1 мы добавили возможность асинхронного кэширования данных на локальных дисках worker-узлов. При попытке доступа к группе записей определенной колонки CedrusData определяет, подлежат ли данные кэшированию согласно заданной конфигурации. Если кэширование включено, то CedrusData асинхронно запишет данные в кэш локального узла. Последующий доступ к данной группе записей будет происходить из кэша, минуя сетевые вызовы. Вместе с тем CedrusData гарантирует, что вы не получите устаревшие данные, путем проверки метаданных файлов озера данных.
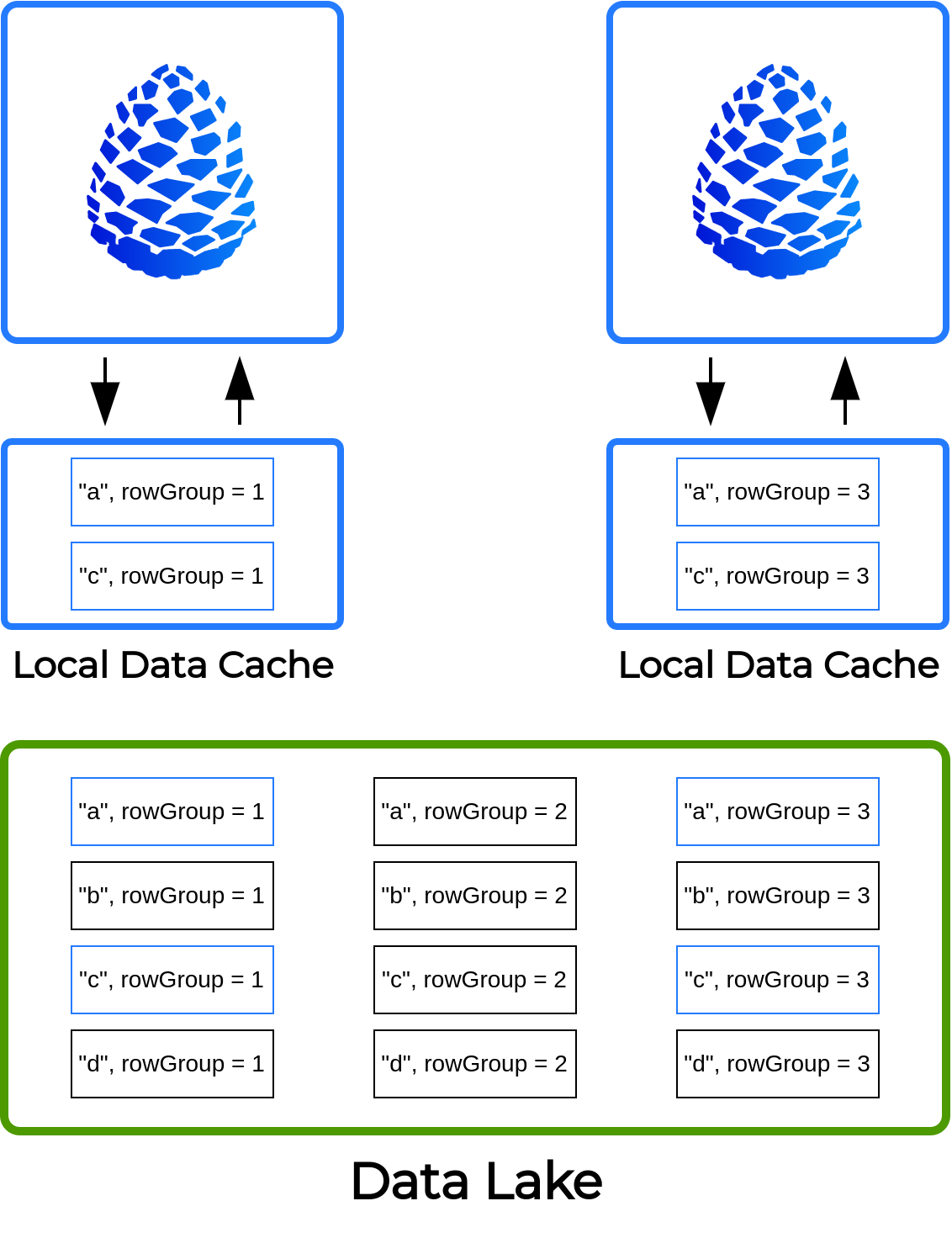
При конфигурировании кэша вы можете задать директорию для хранения закэшированных данных и максимальный размер кэша, указать, какие схемы и таблицы подлежат кэшированию, а так же произвести иные тонкие настройки производительности.
В общем случае Trino может отправлять запросы на чтение одних и тех же данных на разные узлы для балансировки нагрузки, что может негативно сказаться на эффективности кэша. Поэтому в версии CedrusData 417-1 мы так же добавили новый режим распределения чтений по узлам soft affinity. При включении данного режима CedrusData будет стремиться отправлять запросы на чтение одних и тех же данных на одни и те же узлы, тем самым обеспечивая высокий cache hit. Мы рекомендуем всегда включать режим soft affinity при использовании локального дискового кэша. Функционал soft affinity использует алгоритм consistent hashing для предсказуемого распределения запросов на чтение по узлам.
В настоящее время локальное кэширование доступно для коннектора Hive и формата данных Parquet. В последующих релизах мы добавим поддержку большего количества каталогов и форматов данных.
Пример конфигурации локального кэша для каталога Hive с максимальным размером 200 Gb:
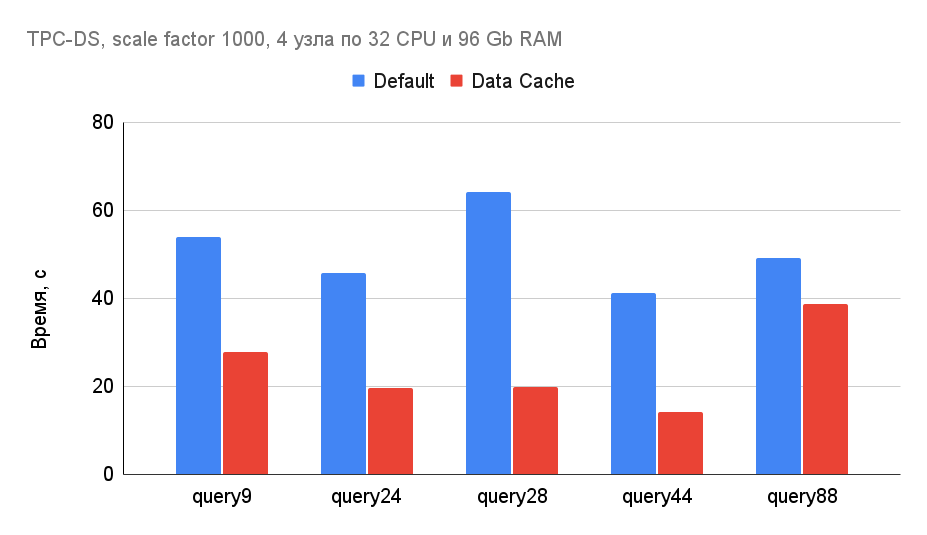
Использование локального кэша во многих случаях приводит к кратному ускорению времени выполнения запросов. Пример ускорения некоторых TPC-DS запросов с помощью локального кэша:
Новый cost-based оптимизатор
При выполнении распределенных SQL-запросов, многие операторы требуют предварительного перераспределения данных в кластере. Так, при выполнении операции `GROUP BY a, b` движок должен убедиться, что все одинаковые пары `[a, b]` будут обработаны на одном узле, так как в противном случае результат агрегации может быть неверным. Схожие требования предъявляют и другие часто используемые операторы, такие как `Join`, `Window`, `Sort`.
В сложных аналитических запросах могут встречаться нетривиальные комбинации операторов с разными требованиями к распределению данных. По умолчанию Trino стремится найти оптимальный план перераспределения данных в окрестностях конкретного оператора, но не может найти глобально оптимальный план, который учитывает требования всех операторов одновременно. Соответствующая логика находится в правиле оптимизации AddExchanges.
В версии CedrusData 417-1 мы добавили новое правило оптимизации, которое позволяет эффективно рассматривать сотни и тысячи альтерантивных способов перераспределения данных одновременно, выбирая наиболее оптимальный на основе стоимости. Новое правило использует алгоритм Cascades (так же используемый в SQL Server и Greenplum) и мемоизацию для генерации множества альтернативных планов. После генерации альтернатив правило использует cost-модель и статистики для выбора наиболее оптимального плана. Это позволяет CedrusData находить нестандартные планы перераспределения данных, которые минимизируют количество передаваемой по сети информации и существенно сокращают время выполнения запросов. Включить новый режим оптимизации можно с помощью следующего параметра в файле `config.properties`:
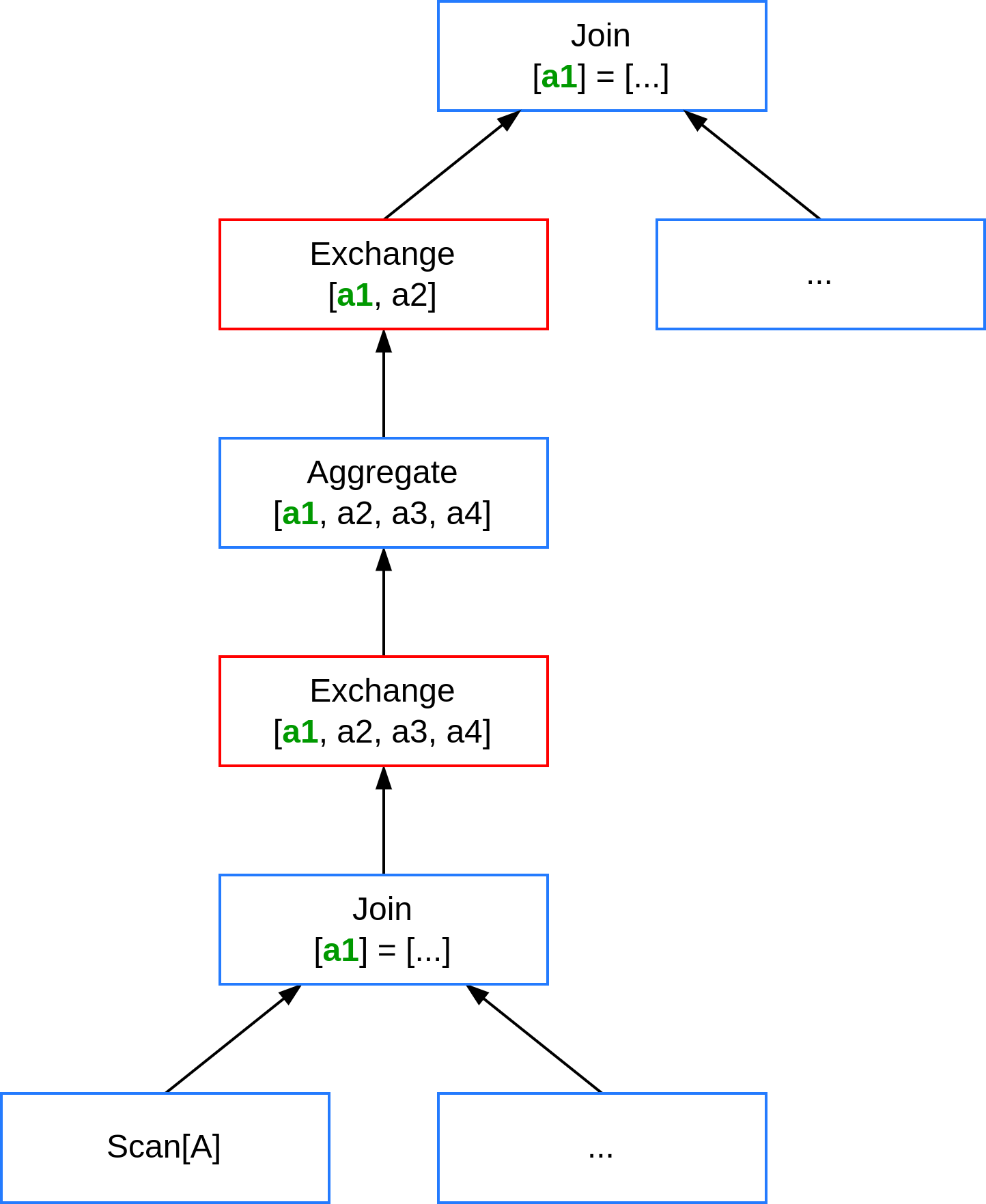
Рассмотрим TPC-DS запрос 39, который представлен несколькими операторами `Join` и `Aggregation`. Каждый оператор выставляет собственные требования к распределению входящего потока данных. Стандартный движок Trino предлагает выполнить такой запрос путем нескольких последовательных перераспределений данных по разным атрибутам (оператор `Exchange`). Данный план не является оптимальным.
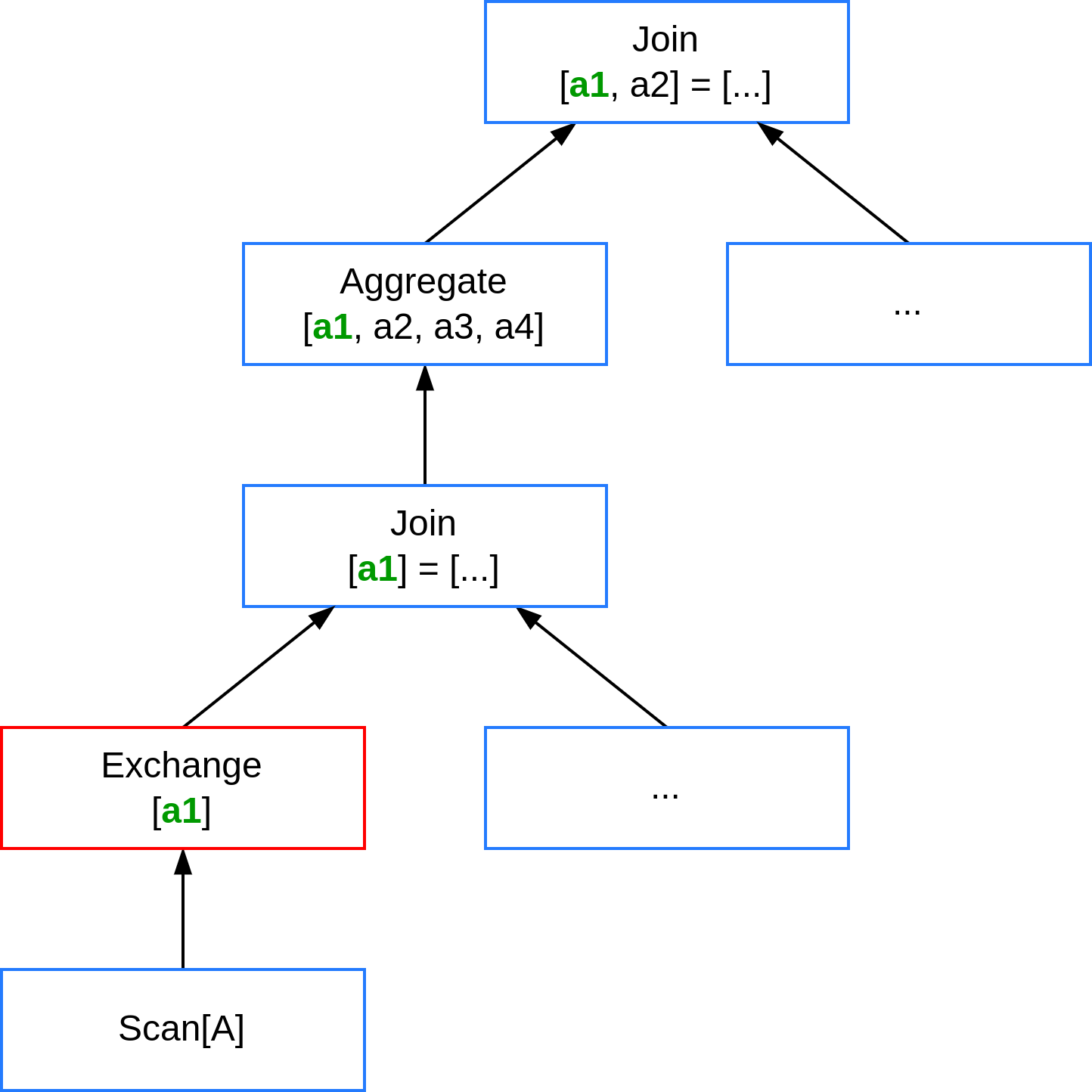
В то же время оптимизатор CedrusData может определить, что ряду операторов требуется партиционирование данных по общему атрибуту `a1`. Таким образом, выполнение того же запроса можно добиться путем единственного перераспределения данных по общему атрибуту на ранних стадиях выполнения запроса. Такой план выполняет тот же самый запрос почти в два раза быстрее.
Использование нового cost-based оптимизатора позволяет существенно ускорить ряд сложных аналитических запросов с большим количеством операций `Join`, `Aggregation` и `Window`. Пример ускорения некоторых TPC-DS запросов с помощью нового оптимизатора:
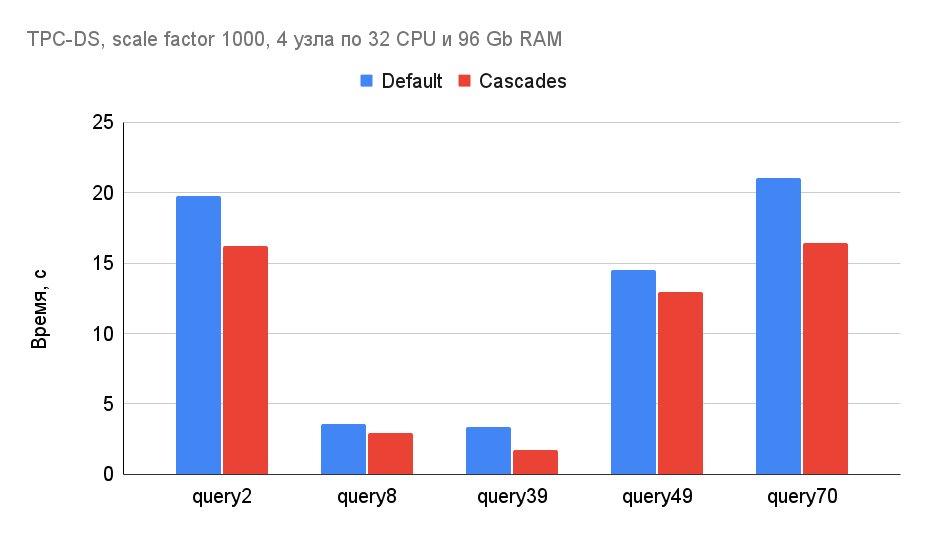
В последующих версиях мы добавим интеграцию Cascades с рядом других важнейших правил оптимизации (например, с правилом планирования порядка Join-ов), что позволит CedrusData находить еще более оптимальные планы.
Коннектор Teradata
Документация: https://docs.cedrusdata.ru/latest/connector/teradata.html.
Начиная с версии 417-1, CedrusData позволяет запускать запросы к аналитической СУБД Teradata. Коннектор поддерживает pushdown предикатов, а так же операций `Join`, `Aggregate` и `Limit`, а так же параллельное сканирование таблицы Teradata с нескольких узлов CedrusData.
Для подключения к Teradata вам потребуется самостоятельно скачать JDBC драйвер Teradata из публичного Maven репозитория и добавить его к распакованному дистрибутиву CedrusData. После этого вы можете подключиться к Teradata, задав следующую конфигурацию каталога:
Дальнейшие планы
В настоящий момент вы завершаем тестирование нового режим работы Trino, который позволяет дедуплицировать повторяющиеся операторы в плане запроса. Данная оптимизация позволит значительно ускорить широкий спектр аналитических запросов. Мы так же приступаем к разработке нового UI для запуска SQL запросов и администрирования кластера.
Свяжитесь с нами, что бы узнать больше о CedrusData и Trino.