
Релиз CedrusData 410-1
Ускорение запросов к partitioned таблицам Hive и новый способ аутентификации в JDBC коннекторах

Общая информация
Релиз CedrusData 410-1 вышел 10 марта 2023 года и основан на Trino 410.
Запуск из архива:
Запуск в Docker-контейнере:
Ключевые изменения
Ускорение запросов к partitioned таблицам Hive
Документация: https://docs.cedrusdata.ru/latest/connector/hive.html#hive-partitioned-execution.
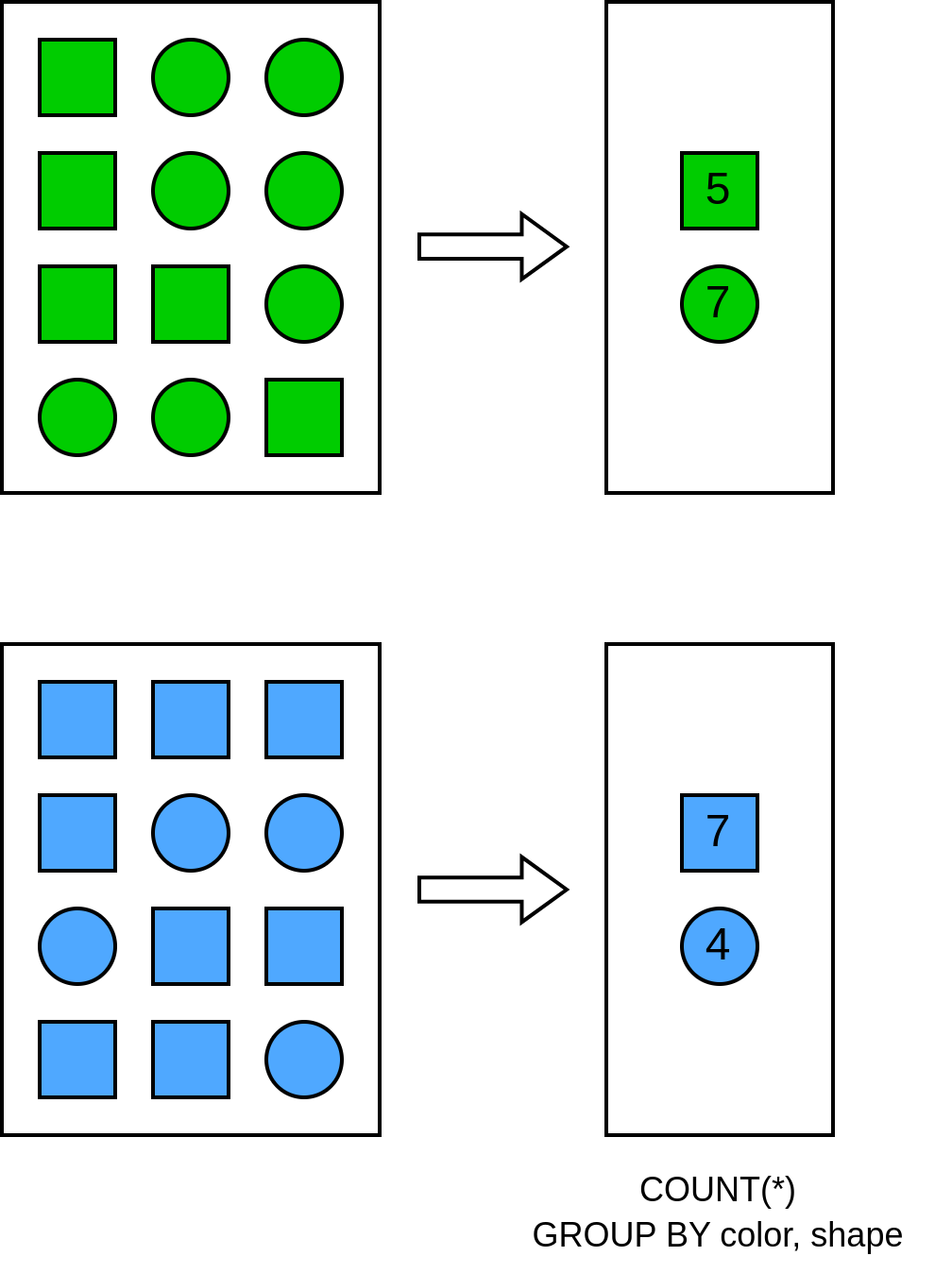
Trino использует информацию о партициях для ускорения запросов. Например, если таблица партиционирована по атрибуту `date`, и запрос имеет условие `WHERE date = '03-10-2023'`, Trino прочитает данные только из одной партиции (partition pruning). Однако, Trino не может использовать информацию о схеме партиционирования таблиц Hive в процессе создания плана запроса.
Например, если таблица `items` партиционирована по атрибуту `color`, и мы хотим сделать агрегацию по атрибутам `color` и `shape`, Trino потребуется два шага для выполнения такой операции: локальная предварительная агрегация и финальная агрегация. Между этими шагами Trino перераспределит данные между узлами (оператор `Exchange`) согласно ключу группировки.
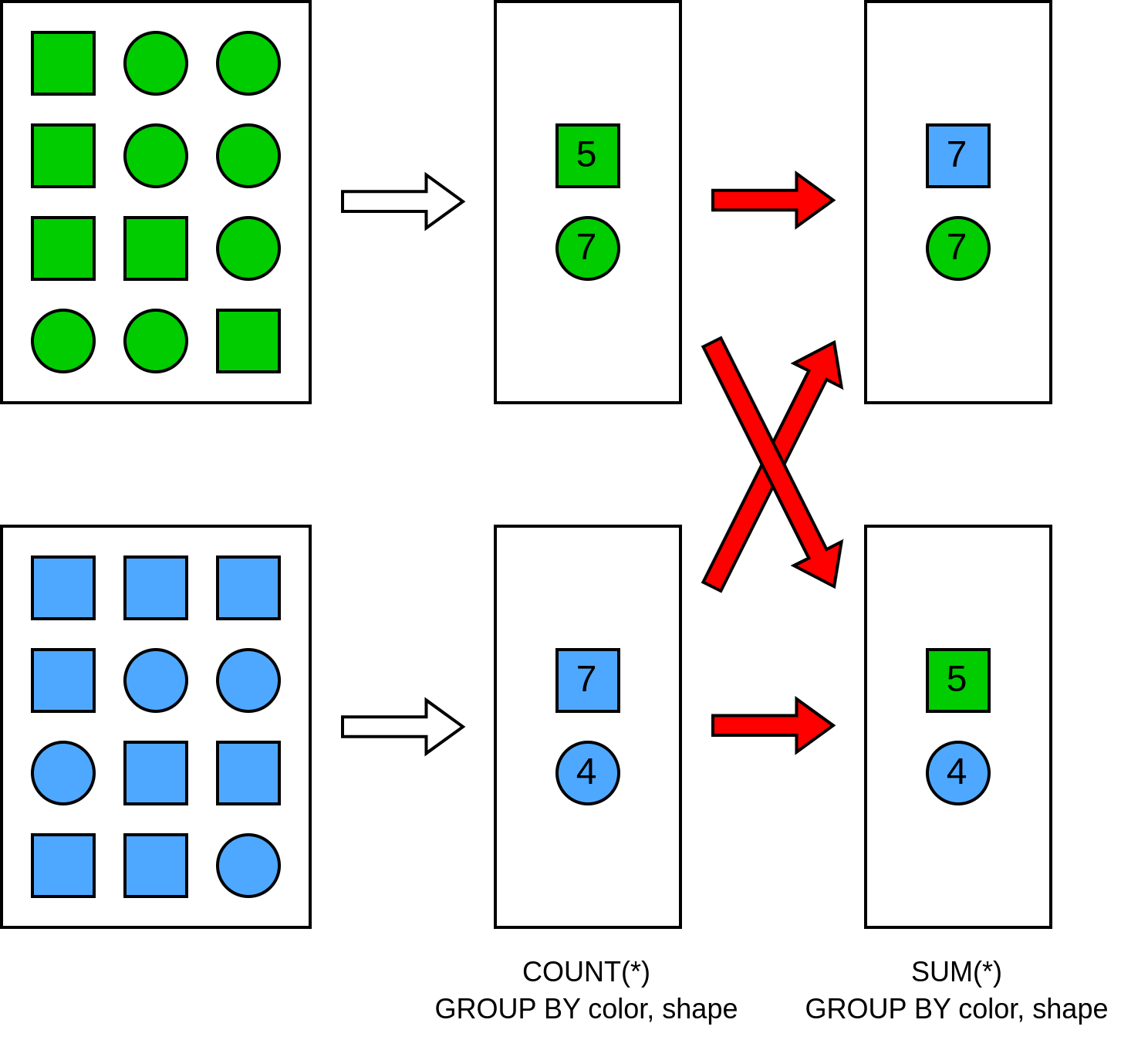
Заметим, что на втором шаге не происходит какой-либо полезной работы, так как благодаря партиционированию по атрибуту `color` финальные значения агрегатов можно посчитать без перераспределения данных между узлами. Оптимизатор Trino не использует информацию о партиционировании таблиц Hive в процессе планирования, а потому не может знать, что второй шаг агрегации избыточен.
В CedrusData оптимизатор имеет доступ к информации о партиционировании таблиц Hive, что позволяет выбрать более оптимальный план запроса:
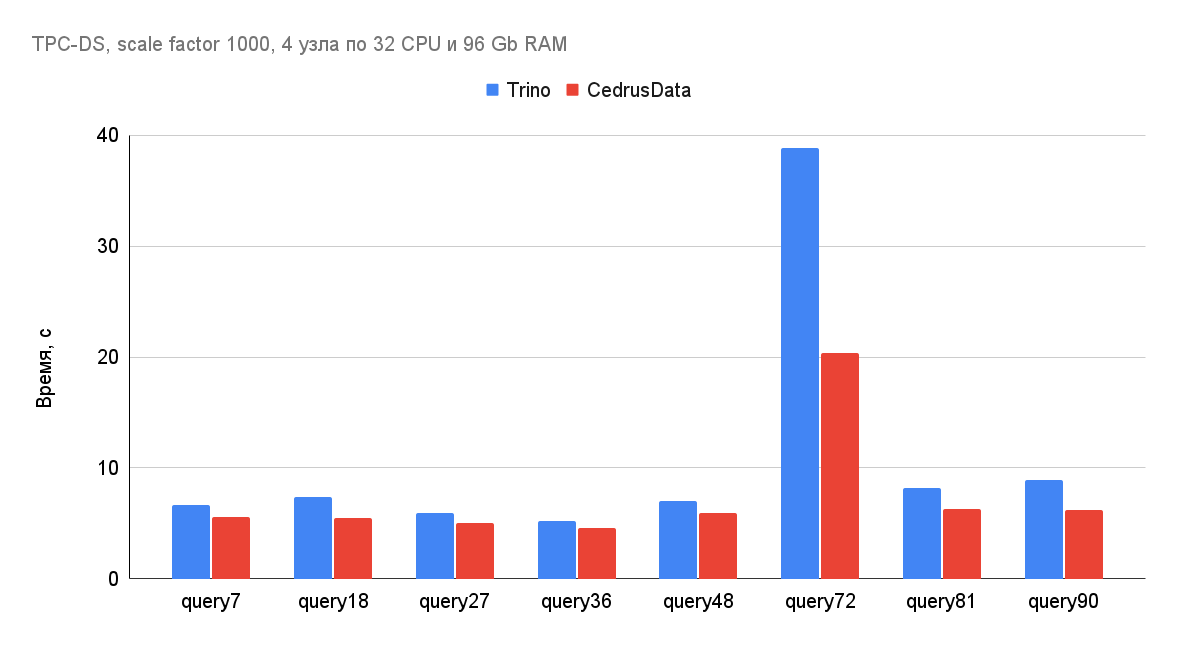
Данная оптимизация ускоряет операторы Join, Aggregate, Window, а так же ряд других операторов. Ниже приведены примеры TPC-DS запросов, которые получили ускорение благодаря данной оптимизации. Обратите внимение, что время выполнения запроса 72 уменьшилось с 38 секунд до 20. К сожалению, потенциал этого изменения не может быть раскрыт в полной мере в текущей версии CedrusData, так как оптимизатор Trino имеет ограничения, не позволяющие использовать информацию о партиционировании таблиц в ряде случаев. Мы активно работаем над преодолением данных ограничений и в следующих версиях CedrusData мы ожидаем прирост производительности в большем количестве запросов.
Более подробную информацию о способах передачи данных между узлами в распределенных системах можно найти в нашем блоге Introduction to Data Shuffling in Distributed SQL Engines.
Аутентификация в коннекторах от имени текущего пользователя
Документация: https://docs.cedrusdata.ru/latest/security/connector-authentication.html.
Большинство коннекторов CedrusData предполагают наличие сервисного аккаунта в источнике данных. Таким образом, выполнение команд к источнику от всех пользователей происходит через один аккаунт. Это затрудняет разграничение прав доступа между пользователями и влечет дополнительные административные издержки.

В CedrusData появилась возможность аутентификации в ряде коннекторов от имени текущего пользователя CedrusData. Таким образом, пользователи CedrusData могут работать с одним и тем же источником данных с разными правами доступа. В настоящий момент данный механизм аутентификации поддерживается только для JDBC источников (Greenplum, ClickHouse, Postgres, MySQL, Oracle, SQL Server, Apache Ignite).

Следует отметить, что данный мезанизм аутентификации не всегда удобен, так как требует наличия одинаковых учетных записей в CedrusData и источнике. В следующих релизах мы добавим дополнительные способы аутентификации и имперсонации пользователей в источниках на основе ролей.
Дальнейшие планы
В настоящий момент мы работаем над дальнейшими улучшениями оптимизатора Trino, которые позволят во многих случаях ускорить запросы за счет уменьшения количества данных, передаваемых между узлами. Мы так же завершаем прототипирование нового способа выполнения запросов с переиспользованием результатов идентичных фрагментов вместо их повтороного выполнения. Мы ведем работу над новым JDBC коннектором общего назначения, который позволит подключаться к JDBC-совместимым источникам данных. Наконец, мы работаем над более удобными механизмами аутентификации и авторизации пользователей в CedrusData и источниках данных.
Свяжитесь с нами, что бы узнать больше о CedrusData и Trino.