

Архитектура оптимизатора Trino
Trino это распределенный SQL-движок для больших данных. В данной статье мы рассмотрим устройство оптимизатора запросов Trino: реляционное представление операторов, интерфейс оптимизатора, алгоритм применения трансформаций.

Введение
Trino это распределенный open-source SQL-движок для больших данных. Trino имеет массивно-параллельную архитектуру и содержит широкий набор коннекторов к различным системам, включая реляционные и NoSQL СУБД, и экосистему Hadoop. Это позволяет Trino выполнять сложные федеративные запросы к нескольким системам.
При получении запроса, Trino должен принять решение, какие вычисления и в каком порядке выполнить самостоятельно, а какие отправить в коннекторы (pushdown). Для этого Trino использует сложный rule-based оптимизатор запросов, архитектуру которого мы рассмотрим в данной статье.
Реляционное Дерево
Оптимизаторы SQL-запросов наиболее часто используют одну из двух моделей промежуточного представления:
- Abstract syntax tree (AST) - оптимизатор производит трансформации непосредственно над синтаксическим деревом, полученным в процессе парсинга запроса. Такой подход легок в реализации, так как все SQL-движки в обязательном порядке имеют парсер, а значит структура дерева уже определена. Недостатком является высокая сложность реализации трансформаций поверх синтаксического дерева. Примером системы с таким оптимизатором является Postgres.
- Relational tree - оптимизатор производит трансформации над деревом реляционных операторов, таких как `Project`, `Filter`, `Aggregate` или `Join`. Реляционное представление значительно облегчает реализацию трансформаций, но требует дополнительный шаг для конвертации синтаксического дерева в реляционное дерево. Большинство современных оптимизаторов используют такой подход ввиду его высокой гибкости.
Оптимизатор Trino так же использует реляционное дерево в качестве промежуточного представления:
- Парсер на основе ANTLR конвертирует запрос в синтаксическое дерево.
- Семантический анализатор проверяет дерево на предмет логических ошибок, и обогащает его информацией о типах данных и используемых функциях.
- RelationalPlanner преобразует синтаксическое дерево в дерево реляционных операторов. Примеры операторов: TableScanNode, ProjectNode, FilterNode, AggregationNode, JoinNode.
Рассмотрим следующий запрос:
После преобразования в реляционное дерево, мы получим следующий логический план:

Для последующих трансформаций Trino использует исключительно реляционное представление. Процесс оптимизации разбит на несколько десятков фаз. Каждая фаза реализует интерфейс PlanOptimizer, который принимает текущее реляционное дерево, и возвращает трансформированное.
Некоторые фазы реализуют паттерн visitor, преобразуя дерево в процессе его направленного обхода. Например, фаза PredicatePushDown стремится переместить фильтры вниз по реляционному дереву. Однако большинство фаз представляют собой rule-based трансформации.
IterativeOptimizer
Rule-based оптимизация в Trino реализована с помощью итеративного драйвера IterativeOptimizer. Сначала драйвер записывает текущий план в специальную структуру данных Memo, в которой с каждым реляционным узлом сопоставляется вспомогательная информация, такая как входящие ссылки от других узлов.
Далее `IterativeOptimizer` проходит по дереву реляционных операторов сверху вниз. Для каждого оператора мы определяем набор подходящих правил трансформации на основе их паттернов, после чего применяем правила один за другим. Получив новый узел, мы повторяем процесс оптимизации для дочерних узлов. Изменение дочернего узла может открыть новые оптимизации для текущего узла, которые были недоступны ранее. Поэтому процесс top-down оптимизации повторяется в цикле до тех пор, пока не перестают изменяться дочерние узлы.
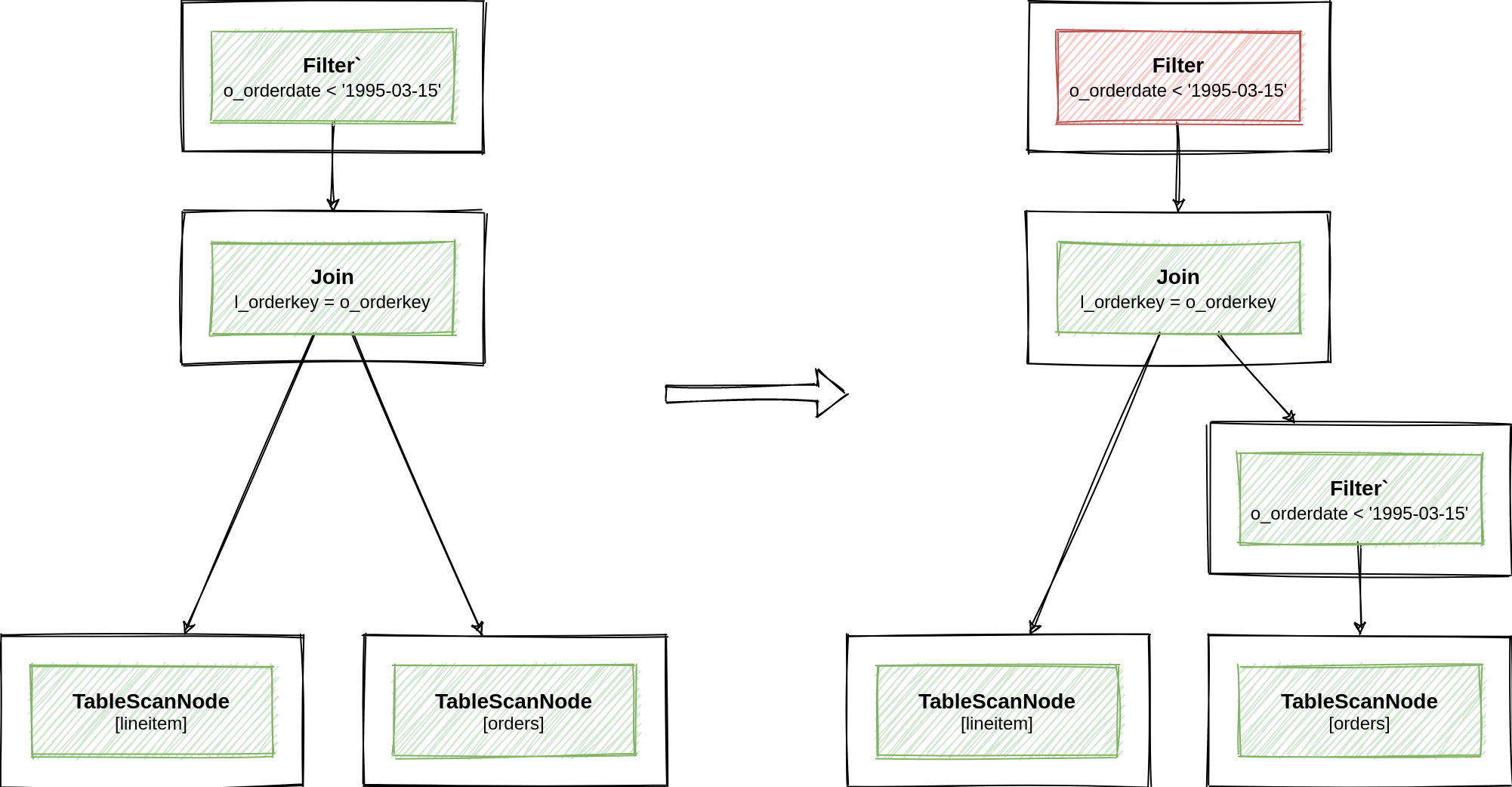
Данный алгоритм является эвристическим и не может гарантировать оптимальность плана. Он схож с алгоритмом `HepPlanner` Apache Calcite и фазой нормализации в CockroachDB, которые мы рассматривали в статье про rule-based оптимизацию.
Перспективы Cost-Based Оптимизации
Любопытно, что в Trino частично присутствует инфраструктура для полноценной cost-based оптимизации:
- Структура данных`Memo` вводит понятие группы эквивалентности, характерное для cost-based оптимизаторов. Но если в cost-based оптимизаторах группа эквивалентности может содержать множество альтернативных планов, то в Trino для каждой группы возможен только один план.
- Принцип обхода дерева сверху вниз с возможностью реоптимизации родительских узлов при изменении дочерних характерен для популярного cost-based алгоритма Cascades, реализованного в SQL Server, Apache Calcite, CockroadchDB, и многих других системах.
- Наконец, в Trino присутствует базовая инфраструктура расчета статистик и стоимости узлов, которая имеет критическое значение для эффективной cost-based оптимизации.
Это показывает, что на разных этапах создания Trino, разработчики держали в уме возможность внедрения полноценной cost-based оптимизации. Эта идея так же упоминается в оригинальной публикации Presto, форком которого является Trino:
We are in the process of enhancing the optimizer to perform a more comprehensive exploration of the search space using a cost-based evaluation of plans based on the techniques introduced by the Cascades framework.
Однако, Cascades в Trino по-прежнему не реализован, а cost-based принципы применены только в отдельных правилах трансформации. Например, правило ReorderJoins генерирует альтернативные порядки Join-ов, и выбирает наиболее дешевый на основе стоимости.
Расширение возможностей cost-based оптимизации остается одной из ключевых задач сообщества Trino, так как она может существенно улучшить производительность системы в целом. Наша команда занимается исследованием и прототипированием данного подхода.
Правила
Интерфейс правила Rule является универсальным, и позволяет закодировать произвольную трансформацию. Trino содержит около 200 правил, которые решают широкий спектр задач. Наиболее важные группы задач:
- Нормализация - некоторые правила позволяют избавиться от сложных конструкций, что бы упростить последующие оптимизации и реализацию движка выполнения запросов. Пример: нормализация выражений.
- Оптимизация - ряд правил направлены на переписывании дерева в более оптимальную форму. Например, существует набор правил, которые удаляют неиспользуемые колонки, тем самым минимизируя объем данных, передаваемых между операторами. Другим важным примером являются pushdown трансформации, которые переставляют определенные операторы вниз с целью удешевления плана. Наиболее известной является оптимизация filter pushdown. Но так же возможен pushdown операторов `Project`, `Aggregation`, `Limit` и других.
Все применяемые шаги и правила оптимизации в Trino определены в классе PlanOptimizers.
Заключение
Оптимизатор Trino использует rule-based оптимизацию. Промежуточным представлением является дерево реляционных операторов, а большинство правил трансформации направлено на нормализацию или упрощение.
Trino использует итеративный планировщик, который безусловно применяет правила к текущему дереву сверху вниз. Итеративный оптимизатор не использует cost-based оптимизацию. Тем не менее отдельные правила могут генерировать несколько планов, и выбирать наиболее дешевый из них. Пример такого правила является правило `ReorderJoins`, которое находит оптимальный порядок Join-ов. Разработка полноценного cost-based остается одной из ключевых задач сообщества Trino.
В следующих статьях мы более подробно рассмотрим, как устроено планирование порядка Join-ов в Trino, а так же каким образом происходит pushdown вычислений в источники данных.