

Как развернуть Hive Metastore для работы с CedrusData
Hive Metastore это сервис управления метаданным для озер данных (data lakes). В данной статье мы рассмотрим процесс развертывания Hive Metastore для работы с данными в локальной файловой системе. Такая инсталляция хорошо подходит для экспериментов и изучения продуктов, которые требуют наличия Hive Metastore.

Введение
Hive Metastore это сервис управления метаданным для озер данных (data lakes). В данной статье мы рассмотрим процесс развертывания Hive Metastore для работы с данными в локальной файловой системе. Такая инсталляция хорошо подходит для экспериментов и изучения продуктов, которые требуют наличия Hive Metastore, включая CedrusData и Trino.
Статья содержит пошаговые инструкции по установке Hive Metastore, а так же демонстрирует работу с развернутым Hive Metastore с помощью Hive коннектора CedrusData. Мы будем использовать локальную файловую систему для хранения данных и СУБД Postgres в Docker-контейнере для хранения метаданных.
Процесс развертывания занимает порядка 10-15 минут.
Данная инструкция так же доступна в документации CedrusData.
Что такое Hive Metastore
Озеро данных (data lake) это совокупность файлов, хранящихся в файловой системе (например, HDFS или локальная файловая система) или облаке (например, S3).
Для извлечения информации из файлов с помощью SQL необходимы метаданные, которые описывают, как представить информацию из файлов в виде реляционных таблиц. Примерами метаданных являются информация о путях к файлам, информация о колонках и типах данных, информация о partitioning. Hive Metastore представляет собой сервис управления метаданными.
Исторически Hive Metastore был частью инсталляции Hive, распределенного SQL-движка, который позволяет выполнять SQL-запросы к большим данным с помощью map-reduce задач Hadoop. Со временем популярность Hadoop и Hive уменьшилась, уступив место таким продуктам, как Spark и Trino. Так как Hive Metastore по-прежнему достаточно хорошо справляется с задачами управления метаданным, его продолжают использовать в инсталляциях Spark, Trino и ряда других продуктов в качестве изолированного компонента. Hive Metastore не требует развертывания Hadoop или Hive, но зависит от некоторых библиотек Hadoop.
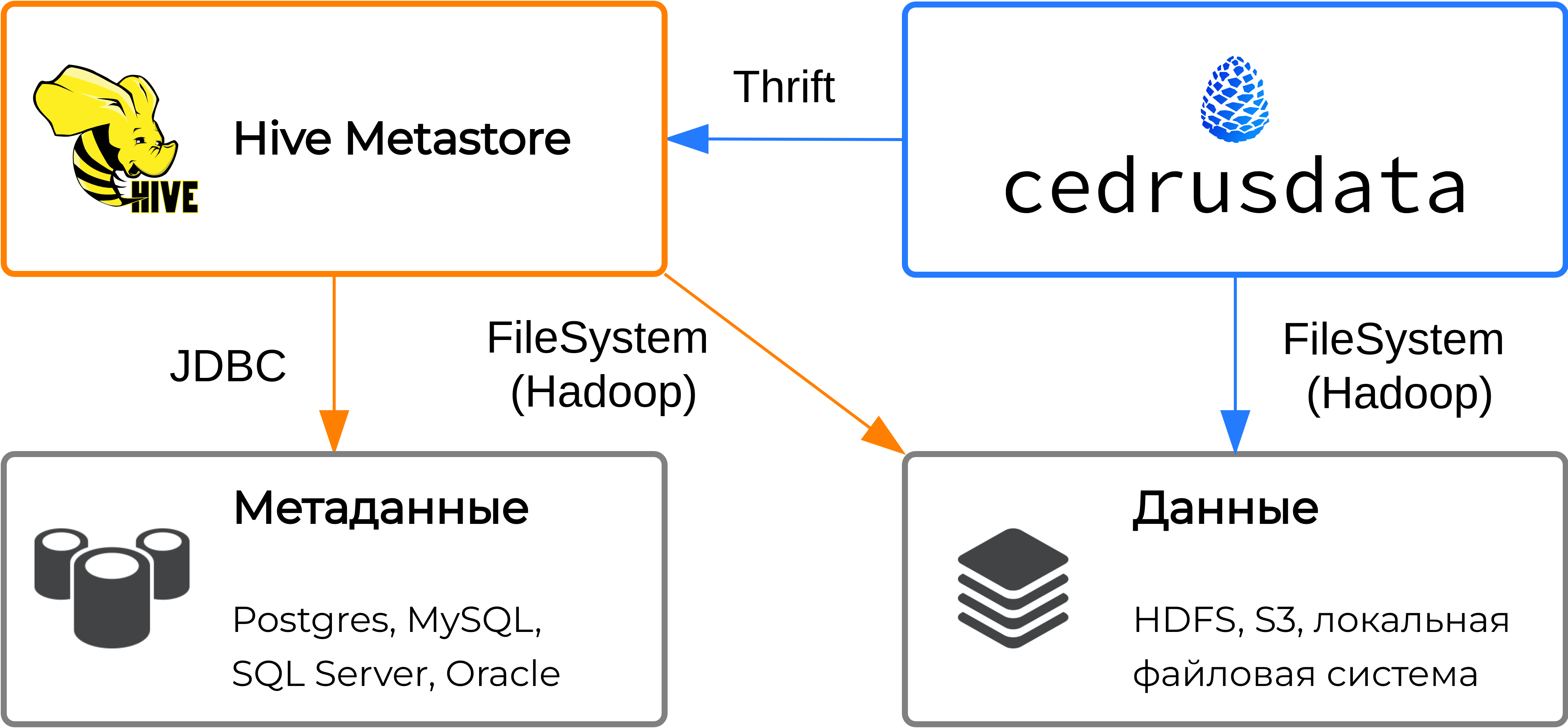
Архитектура Hive Metastore
Hive Metastore получает запросы на чтение или изменение метаданных от сторонних приложений через встроенный сервер, который работает по протоколу Thrift.
Hive Metastore хранит метаданные в сторонней базе данных для обеспечения сохранности информации в случае перезапуска сервиса. При получении запроса, Hive Metastore получает или обновляет необходимые метаданные в базе данных через интерфейс JDBC.
Некоторые запросы к Hive Metastore требуют изменение данных непосредственно в файловой системе. Например, при получении запроса на создание схемы, необходимо директорию схемы в файловой системе, а при получении запроса на удаление таблицы, необходимо удалить соответствующие файлы. Для выполнения операций над файловой системой, Hive использует интерфейс Hadoop FileSystem. Файловая система (или ее абстракция) может требовать специфичную конфигурацию. Так, для работы с данными в локальной файловой системе необходимо знать директорию, в которой хранятся данные, а для работы с данными в S3 необходимо предоставить URL и ключи доступа к object storage.
Конфигурация Hive Metastore
Процесс конфигурации Hive Metastore состоит из следующих шагов:
- Конфигурация сервера Thrift.
- Конфигурация подключения к базе данных, которая хранит метаинформацию.
- Конфигурация доступа к файловым системам, в которых хранятся данные.
Развертывание Hive Metastore
Инструкции ниже приведены для операционных систем Ubuntu/Debian с использованием сетевых портов по умолчанию. Адаптируйте инструкции, если вы используете другую операционную систему, или если у вас возникает конфликт портов.
Шаг 1. Убедитесь, что у вас установлена JDK 8 или выше. Мы рекомендуем использовать Eclipse Temurin JDK 17, которую можно установить с помощью следующих команд:
Шаг 2. Убедитесь, что у вас установлен Docker и что команда docker не требует `sudo`.
Шаг 3. Запустите экземпляр Postgres в Docker-контейнере:
Шаг 4. Создайте директорию в локальной файловой системе, в которой будут храниться данные. Владельцем директории должен быть пользователь, от имени которого будет запущен Hive Metastore. В данном примере мы создаем директорию `/home/hive` и меняем владельца на текущего пользователя:
Шаг 5. Скачайте и распакуйте дистрибутив Hadoop:
Шаг 6. Скачайте и распакуйте дистрибутив Hive Metastore:
Шаг 7. Скачайте JDBC драйвер Postgres, и переместите его в поддиректорию `lib/` в директории дистрибутива Hive Metastore:
Шаг 8. В директории дистрибутива Hive Metastore задайте следующее содержимое файлу `conf/metastore-site.xml`. Важными значениями являются (1) порт сервера Thrift в параметрах `hive.metastore.port` и `metastore.thrift.uris`, (2) порт Postgres в параметре `javax.jdo.option.ConnectionURL` и (3) директория, в которой будут храниться данные в параметре ``metastore.warehouse.dir``. Измените соответствующие параметры, если вы используете другие порты или другую директорию.
Шаг 9. Задайте переменные окружения `JAVA_HOME` и `HADOOP_HOME`:
Во многих случаях директорию установки JDK можно узнать с помощью следующей команды:
Шаг 10. Из директории дистрибутива Hive Metastore инициализируйте схему Hive Metastore в Postgres:
Шаг 11. Из директории дистрибутива Hive Metastore запустите Hive Metastore:
На этом процесс развертывания Hive Metastore завершен.
Проверка работы Hive Metastore с CedrusData
Для проверки работы Hive Metastore с CedrusData, мы запустим узел CedrusData со сконфигурированным каталогом Hive коннектора, после чего выполним ряд SQL-запросов.
Шаг 1. Установите CedrusData из архива согласно инструкции.
Шаг 2. Сконфигурируйте каталог для работы с Hive Metastore. Для этого в директории CedrusData создайте файл `etc/catalog/hive.properties` со следующим содержимым:
Шаг 3. Из директории дистрибутива CedrusData перезапустите узел:
Шаг 4. Из директории дистрибутива CedrusData выполните следующие команды для создания схемы в Hive Metastore, и создания и наполнения таблицы `call_center` в формате Parquet:
Шаг 5. Из директории дистрибутива CedrusData выполните следующую команду для чтения данных из таблицы `call_center`:
Шаг 6. Убедитесь, что в директории Hive Metastore `/home/hive` появился файл таблицы `call_center`:
Шаг 7. Из директории дистрибутива CedrusData выполните следующие команды для удаления таблицы и схемы в Hive Metastore:
Шаг 8. Убедитесь, что директория Hive Metastore `/home/hive` больше не содержит вложенных файлов и директорий:
Следующие шаги
В данной статье мы развернули экзепмляр Hive Metastore, настроили его для работы с локальной файловой системой, после чего запустили SQL-запросы к Hive Metastore из CedrusData.
Вы можете продолжить знакомство с возможностями CedrusData по работе с озерами данных с помощью документации Hive коннектора и других руководств.